Language and vision models are the two frontiers of AI research and product engineering. Language models are mature enough to be many people’s first stop for information. The early products powered by LLMs have changed how many search and learn. For example, I have used ChatGPT and Perplexity more than Google Search in the past 3 months. Image models also power useful products. For example, the most popular photo or social medial editing tools incorporate elements powered by image foundation models, e.g. Photoshop Firefly and Midjourney. Chatting and image editing products have already achieved mainstream adoption, demonstrating that they are both futuristic and practical.
Video models are still experimental. Since the unveiling of Sora in February this year, video models have been one of the competitive frontiers for top industrial AI labs1. Many of these teams put enormous resources and focus on video generation. Numerous companies release their models, some in the form of paid trials and some in the form of just announcements and sample prompt-video pairs. They are still not packaged as useful products yet. The products are just a thin proxy to the underlying models. AI powered video editing is still not available.
In this blog post, I am going to use two examples to draw out the basics of what video models look like today. This minimum technical background will allow us to understand how most video generation model is constructed, trained, and used for inference. It would give us the ability to think through its relationship to the its adjacent cousins of language and image models. We could also better understand how video models might evolve in the coming 6-18 months.
I picked MovieGen ( PZB+24 ) and VideoPoet ( KYG+24 ) as the two representative models for a deep dive. MovieGen is a good case study because it is one of the current state-of-the-arts, and the only leading project that releases substantial details about its data, engineering, and design space. Its design choices should be representative of the approaches that everyone else is fast copying. VideoPoet represents the best of open-source models before Sora turned video generation into a completely closed-source field. VideoPoet was also interesting because it crucially does not use DiT. Its technology illustrates alternative design choices that the video model community has more or less abandoned in the last year.
Model 1: Movie Gen¶
Movie Gen is a suite of models that provides vision, audio, and editing capabilities. This post only looks at its video foundation model. I aim to explain model as an illustrative example of most of the contemporary video foundation models. I break the model down into a few key ingredients to make it easier to digest: vision encoder, patchify, classifier free guidance, and flow matching objective. I wrote a previous post about how neural networks are used in generative models. This model can be seen as another example within that framework.
The encoded videos are then patchified to produce a 1D vector, analogous to a sequence of text tokens in the LLM world. The “tokens” are fed into a neural network. The conditional information (i.e. the prompt) is tokenized and fed into the same network. The neural network crunches these inputs, i.e the video and the text, and outputs a video of bounded length.
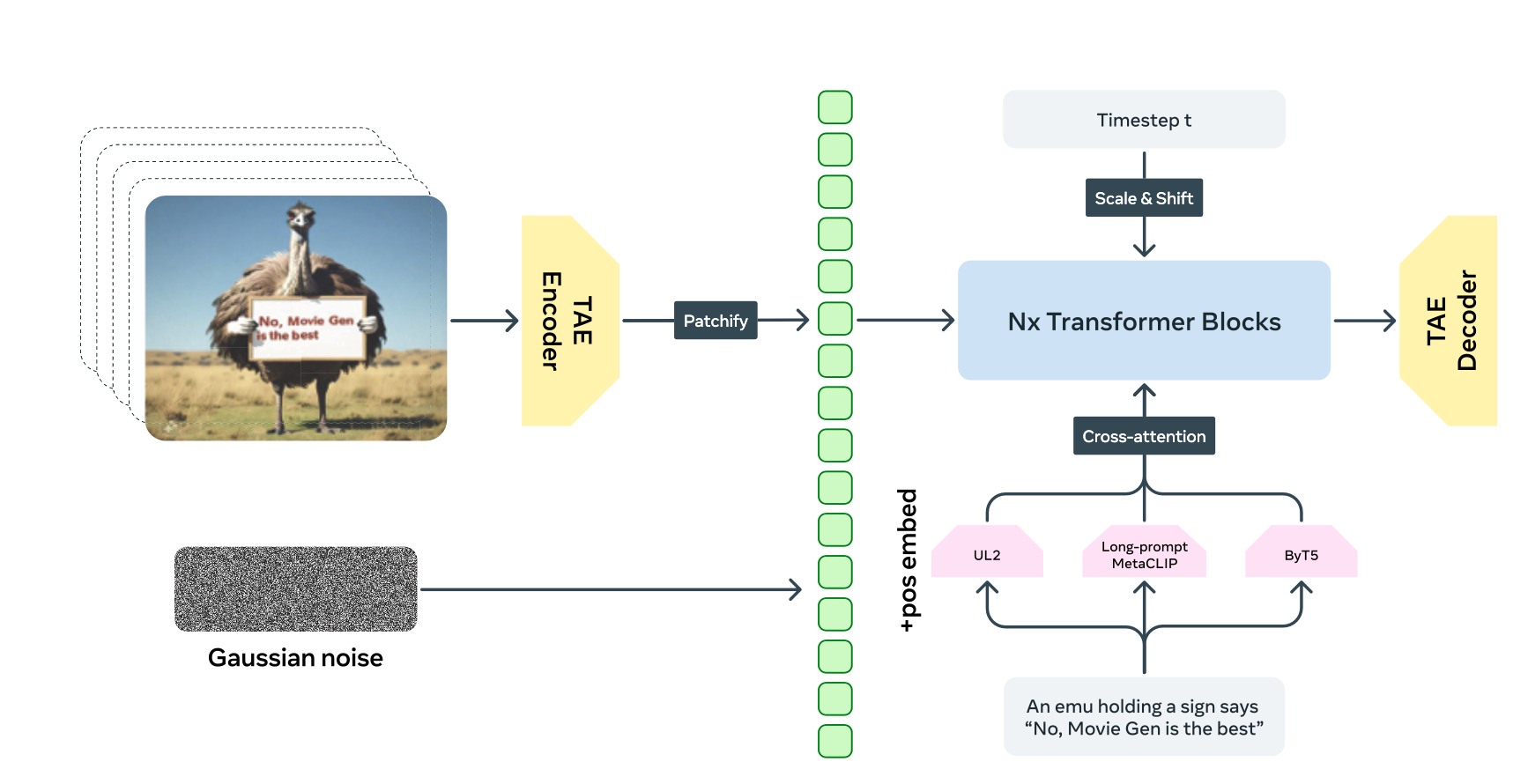
The Temporal Autoencoder (TAE)¶
TAE is a variation of VQ-VAE even though its input is video data. Let \(X_0\) be the pure noise video data. \(X_T\) is the uncorrupted video. It has the shape of \(T' \times H' \times W' \times 3\). \(T'\) is the temporal dimension, represented the length of the video in number of frames. Each frame is \(H' \times W'\). The purpose of TAE is to compress the input into something more manageable and computationally feasible, say \(T \times H \times W \times C\), where \(C\) is a convenient number, for example \(16\). The encoder first convolutes temporally and then convolute spatially. This reduces the overall dimensionality. Each “frame” goes through an attention block, and then temporal attention is applied. At this point, there are \(T \times H \times W \times C\) embeddings. Because of the convolution and attention, each embedding contains local and global information in both the temporal and spatial direction. After applying quantization, the video is represented by an element in \(\{1, ... K\}^{T \times H \times W \times C}\), where \(K\) is the size of the discrete latent space. Both reducing the size of \(T, H, W\) and dropping the embedding dimension greatly reduce the dimensionality. See my previous post and vdOVK18 for more details, and these concepts in the image space. The video space adds the time component. It is fundamentally the same, it just adds more accounting.
Patchify¶
Patchify is a deterministic operation that re-arranges the input into a 1D vector. A patch could be considered as a sub-video both in the temporal and spatial dimension. For example, one patch represent 5 frames, each frame is only the upper right corder. Say we use patch numbers \(P_t\) and \(P_s\). A patch would be a video that has \(P_t\) frames with each frame only has \(P_s \times P_s\) pixels. In our latent space, each patch \(p \in K^{P_t \times P_s \times P_s \times C}\). We treat each patch as a “token”. That is, each token has a dimensionality of \(P_t \times P_s \times P_s \times C\). At this point, the input video becomes a 1D vector. Because everything is flatten, we add the position embedding to retains its positional information. This vector is analogous to the text tokens in LLMs. This paper DBK+21 first uses this technique.
Classifier Free Guidance (CFG)¶
Another key component is how to guide the video generation based on some text prompts. It has become standard practice to use the approach of classifier free guidance. The text is tokenized by a pre-trained tokenizer. The tokens are fed through transformers and combined with the video input coming from the patchified vector. The key difference is that the prompt tokens is controlled by a conditioning variable that probabilistic turning on and off during training. There is also a guidance scale that controls how much this input weighs in the inference stage. See HS22 .
Flow Matching Objective¶
The neural network is trained with a flow matching objective. The combination of TAE, patchify, CFG, and other minor techniques largely describe how to convert the input (video + text) and feed them into a transformer base neural network. There are two key decisions to make about the neural network. One is the internal architecture and the other is the loss objective. As of the writing of this blog, all the top video models uses DiT, where the network backbone uses transformers and the loss objective is diffusion2. The flow matching objective is a generalization of diffusion. This sounds really fancy, but we just have to notes that the neural network crunches all the input as we described, and outputs a generated video \(X\). We calculate the loss,
where \(P\) is the conditioning information from the text prompt, and \(\theta\) represents all the trainable parameters. It is key that \(V_t(X|X_0)\) is directly calculated given a specific probability path description. For the example of gaussian diffusion, \(p_t(X|X_{t-1}) = \mathscr{N}(X|\mu_{t}(X_0), \sigma_{t}(X_0))\). We can get an analytical form
Note that \(u_t\) is the output of the neural network. \(\mathscr{L}\) is easily calculated and we could train on data and update \(\theta\).
Inference starts with a video of pure white noise, \(X_0\). It is encoded by TAE. Using \(u_t(\theta)\) and solving a ODE giving us a probability distribution like description in that we could sample \(X_t\) from \(X_{t-1}\). For each time step, the noisy \(X_t\) get more details through this transformation. The probability path description coming from the flow objective is the same as diffusion. Note that the ODE is not written out here. See my previous post or LCBH+23 for more details.
Model 2: VideoPoet¶
I am doing a deep dive into VideoPoet here because this model was state-of-the-art just two years ago. It contrasts the recent models in crucial ways. It was pre-SORA. At the time of its release, video generation was mostly just research. VideoPoet was not DiT. It uses an autoregressive objective instead of diffusion. This contrast is important to keep in mind because even the most recent models still feel immature. More likely than not, we will see a few more breakthrough moments before visual models reach a similar level of maturity compared to language models.
Having explained MovieGen, understanding VideoPoet is a lot easier. The model converts text, visual, and audio into a single token vector. Each modality has its dedicated tokenizer. The token sequence is fed into a language model, which is trained to predict the next token. The sampling process autoregressively generates a visual token sequence given any partial input sequence. The model decodes the sequence into a video.
Tokenizers¶
The inputs are broken down into text, visual, and sound tokenizer. There are 256 special tokens. These special tokens allow the text, visual, and sound tokens to be delimited. The text tokens are generated by the T5 encoder. MagvitV2 ( YCS+23 , YLG+24 ) is the visual encoder, having a vocab size of 262,144 tokens. The audio tokenizer is SoundsStream ( ZLO+21 ). All the tokens are concatenated into a single sequence.
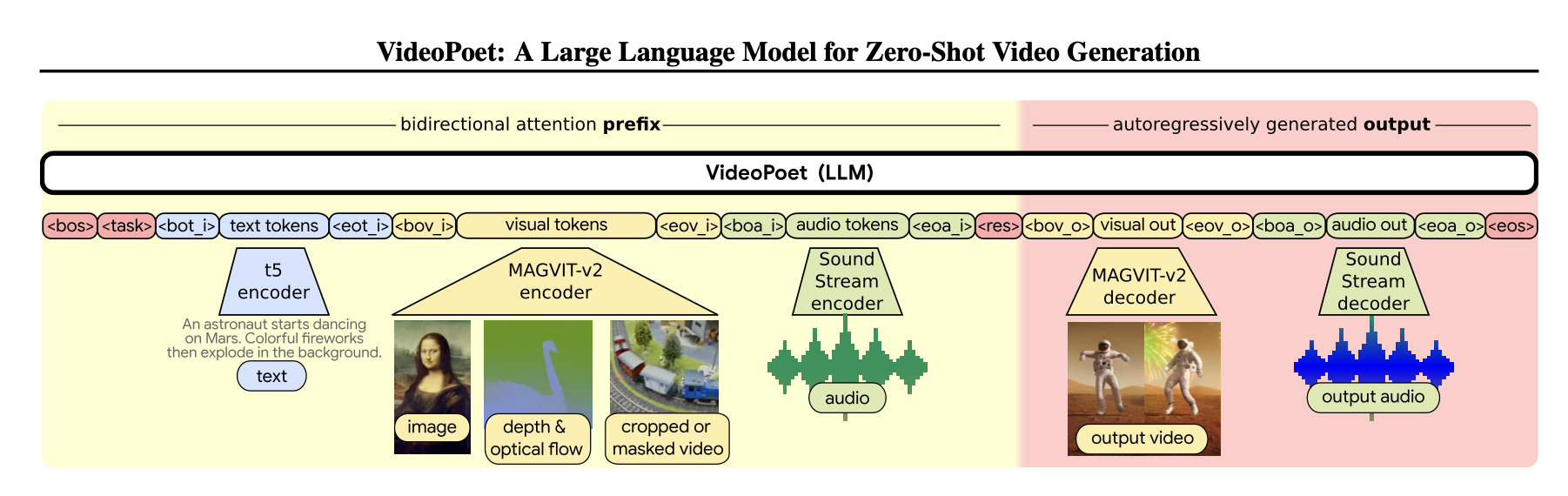
We focus on a bit more details about its visual encoders MagvitV2. It is similar to VQ-VAE. It is different in two key aspects. First is that it aims for a joint image-video tokenization, and second it uses a lookup-free quantization (LFQ) technique to allows the quantization parameter to grow in size. To include temporal information, the encoder primarily use a causal 3D convolution technique. Causal relationship is maintained to ensure that future frame information do not leak. This is important because the encoder are designed to be used for an autoregressive objective.
In VQ-VAE, each embedding \(z \in \mathbb{R}^{d}\) is replaced with \(z \in \{1, ..., K\}\). That is, each embedding is quantized and mapped into a single integer. One critical flaw is that as \(K\) increases, the encoder does not increase in performance. MagvitV2 encoder improves on this by introduce another mapping. It first maps an element in \(\mathbb{R}^{d}\) into \(\{-1, 1\}^{d}\). For each of the dimension, it just retains its signed information. The values gets summed up geometrically to obtain a single number
Autoregressive Objective¶
The model is trained with the objective of predicting the next token. The token sequence uses a shared multimodal vocabulary to represent all the input information (text, audio, and visual). The input is fed through a transformer base language model. The model generates a token sequence in autoregressively. This resembles a prefix, decoder only language model almost exactly. The key difference is the token vocabulary.
Design Space of Video Models¶
Now that we have taken a close look at two of the representative video models. We are equipped with enough background knowledge to discuss what all these AI labs are experimenting and competing on.
DiT and Architecture¶
The most striking fact is that everyone settles on DiT. DiT means that the neural network uses transformers backbone and is trained on a diffusion objective. Before this year, U-Net base on CNNs has the architecture of choice of most image and video diffusion models. The primary reason is that transformers requires quadratic memory relative to input sequence length. But the work of scaling transformers benefit greatly from the research results in language modeling. The memory requirement issue is addressed through more compute resources, more efficient attention mechanisms (e.g. flash attention or windowed attention), and better compressions through encoders. Intuitively, transformers have proven to such a breakthrough architecture in the world LLM, it only makes sense that it should be a key ingredient for visual models, especially as these models scale up.
The choice of diffusion over autoregressive objective is more peculiar. Autoregressive modeling is highly successful in language, but diffusion works better for visual. There are a few things I would like to observe. First, language is intuitive causal. Language is an artificial way to encode information that works well for human. We speak one word after another. Whether intentional or not, autoregressive language model captures this behavior well. However, a visual image is not inherently causal. All the pixels kind of just simultaneously exist. The process of breaking an image down into different sub-images and then piecing them together does not really make sense. I would think about how to realize an image if I were to open my eyes from a deep sleep. First, I just notice a vague outline of the world, and then more details fill in. I start to make sense of the key details that are relevant orient myself in the physical world. My brain does not create visual token after visual token to realize the full image. Furthermore, I actually do not notice all the details, but yet I have a global sense of the what is in front of me. This resembles the diffusion process. In some ways, both autoregression and diffusion are about starting from nothing to building and building more details to complete a bigger objective. In the case of language, it is word after word. In the case of visualization, it is overall details. This blog also makes the connection between autoregression and diffusion. It breaks visual content into a spectral space, and shows that each diffusion step, it is adding more details in different spectra. That is, next token is autoregressive on tokens, and diffusion is autoregressive on spectra.
It is interesting to notice that video does not benefit from a causal rendering that similar to language. For each of the frame or adjacent frame, I suspect it is diffusion is a superior generating process compared to causal rendering like autoregressive. But between scenes, I kind of suspect that some kind of causal objective is more appropriate. Is there a way build a video model that allows visual rendering to be mostly coming from diffusion but temporal content to be driven by some kind of causal objective. Someone would have to make this breakthrough. We might see this in the future. I don’t think diffusion objective is sufficient for generating high fidelity, longer form videos.
Encoders¶
VQ-VAE was a key development demonstrating the power of learned visual representation. It is not surprising that tokenizing text is a more or less a solved problem because text itself is already a well formed abstraction of the physical world. For the example of Byte Pair Encoding, it merely just learns a fixed number, say 30,000, vocabulary from a corpus. That is, its algorithm essentially picks 30,000 subwords. Any new text will be converted into those subwords. On the other hand, visual data is much more raw. An image is composed of pixels, which could be roughly presented by 3 small integer. There just isn’t any natural way to turn them into discrete variables. In order to convert visual information into low dimensional, discrete chunk, the encoder has to be highly intelligent. That means the conversion process itself must be powered by a large neural network.
Every video model actively experiments with the encoder design. The key characteristics is compression rate and representation power. Compression is important because video input consumes a lot of memory. Even a 10 second with a frame rate of 16 fps is too much to feed directly into a DiT network. Representation power could be understood as reconstruction loss. There is a natural tradeoff between compression and representation power. This is a classic problem in information theory. In the ideal world where we have limitless computing power and memory, we would not need to throw away information through lossy encoding. But visual information is still too much to be handled directly in its entirety by large deep network. Encoder design is likely to be an unsolved problem.
Encoders architecture choices are relatively well known. Visual data are usually convoluted in the spatial and temporal dimension to reduce dimensionality. They are further fed into some attention system. We can also add any other neural network structure to the embedding afterward. Dimensionality could be further reduced through some of quantization. These architectural choices are somewhat similar to feature engineering. For each of these components, they have learnable parameters. The vast majority of the intelligence of the encoders is learned from data.
Most of the encoders are still relatively small compared to the main diffusion component. The choice of encoders still has a large impacts on overall model performance. I have not seen anyone really pushes scaling boundary of encoders. Encoders are still less than 1 billion parameters. It might be worthwhile to build a 10 to 50 billion model just for encoding and decoding. The key reason is that the most advanced video models are only in the 10-50 billion parameters range. Visual models haven’t demonstrated the same commercial value compared to language models. Visual models are still early in the product development cycle.
Scaling Estimate¶
The state of the art video models are about 50 billion parameters. GPT4 was already reported in the trillion-parameters range, and that was a year ago. The most advanced LLMs are probably in the 10 trillion range. I take the position that visual system is more complex than language system. A video communicates more information about the physical or abstract concept than language model. Furthermore, if a visual system also generates audio, it is without a doubt that visual system is strictly more capable than language system.
Visual model is more computationally demanding than LLMs. Even a relatively low quality, encoded, 60 seconds video will be 20 MB. An averaged news article is about 1000 words. 1 MB is probably enough to encode 50 articles. One 60 seconds is equivalent to a thousand articles. It is not possible apply self attention naive to a video input. Video model requires a lot more clever techniques to reduce its computation complexity, but it is also fundamentally much more constrained compared to language model.
The two facts that visual model is fundamentally more complex and it is 2 orders of magnitude smaller than language model do not add up. It means only one thing. Visual system is no where near in maturity compared to LLMs. If we rate LLMs as having the reasoning ability of an undergraduate, visual model is more like elementary school. Even if the generated models might look impressive, its internal model of the world is not nearly as sophisticated.
Vision Data¶
Movie Gen uses billions of images and 100s of millions of video clips. Let’s be more concrete. LAION 2B dataset is roughly 500TB. Merlot reserve is about 500TB of data and could be roughly cut into 500 million clips. Just as a point of comparison, gpt4 is reported trained on roughly 15 billion tokens, which is roughly 50 TB of text data. I am sure that Movie Gen uses some of these datasets in additional to other datasets. The combination of LAION 2B and Merlot Reserve are quite representative and in the right order of magnitude in terms of training data for the best of the video foundation models today. I have written my previous post of open source vision dataset that LAION and CommonPool dataset probably already reach the upper limit of what image data the internet can provides. We have much more video data than the typical billion clips range. We should be able to see much better video models in the coming years even just on the expectation that there is a lot of room to grow on video training data.
We could even estimate what is required to create a clean, training-ready video dataset that is in the 10 billion clip range. Say the data team is given 10,000 GPU with Nvidia NVENC. It still takes 10 days to just do one pass on the data that just do a simple encoding/decoding. It might sound hard, but with good enough engineering, this compute infrastructure should be enough. While the GPU could be amortized over the years to do other work, roughly speaking, it is still a 50 million if we assume GPU unit cost of $5000. Other infra cost includes data storage, CPU server, and data transfer. Data acquisition will likely incur direct payments in the million range, if not 10s of millions. We can say we have a 10 person engineering team; while expensive, it is not as much as infra. I would estimate the total cost of that dataset in the range of 100 million dollars. That is expensive! But a lot of teams will pay that kind of cost to develop these models. It should be noted that this cost is just for creating one next-generation video dataset. Training will cost much more.
Judging the details different teams have release, it seems that youtube videos are still make up of the majority of the training data. All the research projects are working hard to get alternative sources. Their focus is likely to be dependent on what they want their models to focus on. Video datasets are more challenging to work with compared to text and even images. They are much bigger. They are not just expensive but also much more demanding on the engineering system to do data transfer and process. They have to be encoded at rest because raw frames are simply too large to store. They require GPUs to to speed up even basic processing such scene cutting, filtering, and captioning. A lot of video data are better protected and less generally available on the internet. Even if some research teams want to be loosey-goosey with compliance, it is still hard for them to get their hands on the vast majority of content from YouTube, movie archives, sports recordings, broadcast studios, and game replays. Texts and images datasets are much easier to create, and at this point, almost all the major industry AI research labs probably end up with more or less the same datasets. It will be interesting to see how video datasets play out in the next few years.
Models Comparison¶
I compiled key metrics about some well-known models3.
| Model | Announced | Org | Openness | Product Trial |
|---|---|---|---|---|
| Imagen Video | 2022-10 | paper | no | |
| Runway Gen-2 | 2023-04 | Runway | closed | paid |
| AnimateDiff | 2023-06 | Tsinghua | open | public |
| Lumiere | 2023-08 | paper | invite only | |
| ModelScope | 2023-08 | Alibaba | open | public |
| Stable Video | 2023-11 | Stability AI | paper | yes |
| Emu Video | 2023-11 | Meta | paper | no |
| VideoPoet | 2023-12 | paper | no | |
| WALT | 2023-12 | paper | no | |
| Sora | 2024-02 | OpenAI | technical report | no |
| Veo | 2024-05 | closed | invite only | |
| Runway Gen-3 | 2024-06 | Runway | closed | paid |
| Open-Sora | 2024-06 | HPCAI Tech | open | public |
| Kling | 2024-06 | Kuaishou | closed | paid |
| PixelDance | 2024-09 | Bytedance | closed | invite only |
| Seaweed | 2024-09 | Bytedance | closed | invite only |
| CogVideo | 2024-09 | Tsinghua | open | public |
| Movie Gen | 2024-10 | Meta | paper | no |
| Model | Size | Data | Architecture | Training Objective |
|---|---|---|---|---|
| Imagen Video | 5.7 billion | 60M image 14M video |
U-Net | diffusion |
| Runway Gen-2 | unknown | unknown | unknown | unknown |
| AnimateDiff | 1 billion | 10M video | adapters | diffusion |
| Lumiere | unknown | 30M video | U-Net | diffusion |
| ModelScope | 1.7 billion | 2B image 10M video |
U-Net | diffusion |
| Stable Video | 1.5 billion | 600M video | transformer | diffusion |
| Emu Video | 4.4 billion | 34M video | U-Net | image diffusion next frame |
| VideoPoet | 8 billion | 1B image 270M vidoes |
MAGVIT-v2 transformer |
next token |
| WALT | 0.5 billion | 970M image 89M video |
MAGVIT-v2 transformer |
diffusion |
| Sora | unknown | unkonwn | transformer | diffusion |
| Veo | unknown | unknown | unknown | unknown |
| Runway Gen-3 | unknown | unknown | unknown | unknown |
| Open-Sora | 1.5 billion | 90M videos | VAE transformer |
diffusion |
| Kling | unknown | unknown | unknown | unknown |
| PixelDance | unknown | unknown | unknown | unknown |
| Seaweed | unknown | unknown | unknown | unknown |
| CogVideo | 5 billion | 2B image 35M video |
VAE expert transformer |
diffusion |
| Movie Gen | 30 billion | O(1)B image O(100)M video |
TAE transformer |
diffusion |
The announcement of Sora was a watershed moment. Before Sora, video models were driven mostly by the research community. When Sora was made public in February, it only released minimal technical details and a limited set of selected prompt-video pairs. Still, it showed the world its enormous commercial potential.
Sora set the trend of being closed source. It was released with limited details, and all subsequent models from industrial labs followed suit, releasing even fewer technical details. For example, there is no public information about the internals of video models such as Kling, Bytedance Seaweed, or Google’s Veo, which are considered competitive with Sora and MovieGen. The only exception is Meta’s MovieGen foundation model. We have to give the Meta team their flowers.
Despite limited public information, we can summarize some major trends of all the cutting-edge models in terms of design choices, model scale, and data. DiT (transformer backbone + diffusion objective) has become dominant after Sora’s technical report. The model scale ranges between 5 to 50 billion parameters. The image data focuses heavily on internet datasets that more or less resembles DataComp and iis in the order of billions of text-image pairs. The video dataset focuses on YouTube and movie clips and ranges between 100 million to 1 billion of 5-20 second clips. These characteristics are typical in all the latest models4. Given the similarity in architecture, data, and model scale, the models’ similar capabilities are not surprising.
Different models have different focuses. For example, some focus on generating movie-quality clips, demonstrating close-up shots, rack focusing, zoom shots, etc. Some focus on consistency in scene changes, and some on motions. In my opinion, all the output videos feel similar. Pre-Sora generated videos look a certain way. They are mostly animated pictures with a low frame rate. The post-Sora videos are similarly recognizable. They are 5-10 seconds long and feel sci-fi and staged. It could not easily generate realistic, real-life clips similar to what I could capture with my phone. Each model tends to do well in some areas but not all. To me, this is evidence that video models are still early in their development cycle. There are still a lot of low-hanging fruits. For each deficient area from one model, other models have already shown it is feasible to overcome that deficiency. Each model focuses on a particular set of data, but no single project team is an order of magnitude better than others. The same could be said about model scale. I would say that if a team possesses sufficient resources, comparable to those used in training GPT4 (in terms of hardware, data, and engineering talent), they should be able to build a model that is significantly superior to the current generation.
The latest video models are mostly closed to the public. I suspect a few reasons. First, inference cost is high. The models are built as research models that are not optimized for production to serve tens or hundreds of millions of users. I tested running a CogVideo 5B model on an 80G A100 GPU in AWS. To generate a reasonable video from a prompt, it took about 3-5 minutes. The cost is about $0.1 per video. That is assuming full GPU utilization over the course I rent the GPU. In practice, the cost per generation is much higher5. Inference will likely require additional optimization both at the model and distributed system level to push inference time from minutes to seconds to provide a reasonable user experience. Second, the models still produce a lot of unrealistic videos. The released prompt-videos pairs are heavily filtered to show their potential. Third, productization is hard. Each AI lab has gotten enormous resources to speed up their foundation model development. Optimizing models for millions of users takes time. Turning foundation models into product features, such as video editing, or multimedia content-creating tools, takes a different set of people and skillsets. High-quality user experiences will take time to emerge.
Footnotes¶
- I would say that the two frontiers in the year of 2024 have been LLMs and video generation. Industrial AI labs are AI teams within large tech corporations or extremely well-funded startup companies. Examples are Google, Facebook, Bytedance, OpenAI, and Anthropic. ↩
- Alternative to transformer is CNN or LSTM. Alternatives to diffusion is an autoregressive objective or direct density estimation. ↩
- An update on 2024-12. This field is moving very fast. In just two months, my tables are already outdated. There are more models to be considered: Pika, Luma, Hunyuan, Haiper, Sora with public access, and Veo 2. Even though some people have asked me to update, I probably won’t. The goal of my notes is only to document a snapshot of my thinking. ↩
- . All the major teams are secretive about their effort. But small tidbits of information leaked in various public reportings. ↩
- Overall utilization is going to be much lower than 80-90%. Ten cents is just the GPU cost. Each interaction with the video model feels a lot like posting an Ethereum transaction. A service is not going to be able to make money from a $20 per month subscription if the product has high engagement. ↩
Citations
- Polyak, Adam, Zohar, Amit, Brown, Andrew, Tjandra, Andros, Sinha, Animesh, Lee, Ann, Vyas, Apoorv, Shi, Bowen, Ma, Chih-Yao, Chuang, Ching-Yao, Yan, David, Choudhary, Dhruv, Wang, Dingkang, Sethi, Geet, Pang, Guan, Ma, Haoyu, Misra, Ishan, Hou, Ji, Wang, Jialiang, Jagadeesh, Kiran, Li, Kunpeng, Zhang, Luxin, Singh, Mannat, Williamson, Mary, Le, Matt, Yu, Matthew, Singh, Mitesh Kumar, Zhang, Peizhao, Vajda, Peter, Duval, Quentin, Girdhar, Rohit, Sumbaly, Roshan, Rambhatla, Sai Saketh, Tsai, Sam, Azadi, Samaneh, Datta, Samyak, Chen, Sanyuan, Bell, Sean, Ramaswamy, Sharadh, Sheynin, Shelly, Bhattacharya, Siddharth, Motwani, Simran, Xu, Tao, Li, Tianhe, Hou, Tingbo, Hsu, Wei-Ning, Yin, Xi, Dai, Xiaoliang, Taigman, Yaniv, Luo, Yaqiao, Liu, Yen-Cheng, Wu, Yi-Chiao, Zhao, Yue, Kirstain, Yuval, He, Zecheng, He, Zijian, Pumarola, Albert, Thabet, Ali, Sanakoyeu, Artsiom, Mallya, Arun, Guo, Baishan, Araya, Boris, Kerr, Breena, Wood, Carleigh, Liu, Ce, Peng, Cen, Vengertsev, Dimitry, Schonfeld, Edgar, Blanchard, Elliot, Juefei-Xu, Felix, Nord, Fraylie, Liang, Jeff, Hoffman, John, Kohler, Jonas, Fire, Kaolin, Sivakumar, Karthik, Chen, Lawrence, Yu, Licheng, Gao, Luya, Georgopoulos, Markos, Moritz, Rashel, Sampson, Sara K., Li, Shikai, Parmeggiani, Simone, Fine, Steve, Fowler, Tara, Petrovic, Vladan, and Du, Yuming. Movie gen: a cast of media foundation models. 2024. URL: https://arxiv.org/abs/2410.13720, arXiv:2410.13720. 1
- Kondratyuk, Dan, Yu, Lijun, Gu, Xiuye, Lezama, José, Huang, Jonathan, Schindler, Grant, Hornung, Rachel, Birodkar, Vighnesh, Yan, Jimmy, Chiu, Ming-Chang, Somandepalli, Krishna, Akbari, Hassan, Alon, Yair, Cheng, Yong, Dillon, Josh, Gupta, Agrim, Hahn, Meera, Hauth, Anja, Hendon, David, Martinez, Alonso, Minnen, David, Sirotenko, Mikhail, Sohn, Kihyuk, Yang, Xuan, Adam, Hartwig, Yang, Ming-Hsuan, Essa, Irfan, Wang, Huisheng, Ross, David A., Seybold, Bryan, and Jiang, Lu. Videopoet: a large language model for zero-shot video generation. 2024. URL: https://arxiv.org/abs/2312.14125, arXiv:2312.14125. 1
- van den Oord, Aaron, Vinyals, Oriol, and Kavukcuoglu, Koray. Neural discrete representation learning. 2018. URL: https://arxiv.org/abs/1711.00937, arXiv:1711.00937. 1 2
- Dosovitskiy, Alexey, Beyer, Lucas, Kolesnikov, Alexander, Weissenborn, Dirk, Zhai, Xiaohua, Unterthiner, Thomas, Dehghani, Mostafa, Minderer, Matthias, Heigold, Georg, Gelly, Sylvain, Uszkoreit, Jakob, and Houlsby, Neil. An image is worth 16x16 words: transformers for image recognition at scale. 2021. URL: https://arxiv.org/abs/2010.11929, arXiv:2010.11929. 1 2
- Ho, Jonathan and Salimans, Tim. Classifier-free diffusion guidance. 2022. URL: https://arxiv.org/abs/2207.12598, arXiv:2207.12598. 1
- Lipman, Yaron, Chen, Ricky T. Q., Ben-Hamu, Heli, Nickel, Maximilian, and Le, Matt. Flow matching for generative modeling. 2023. URL: https://arxiv.org/abs/2210.02747, arXiv:2210.02747. 1
- Yu, Lijun, Cheng, Yong, Sohn, Kihyuk, Lezama, José, Zhang, Han, Chang, Huiwen, Hauptmann, Alexander G., Yang, Ming-Hsuan, Hao, Yuan, Essa, Irfan, and Jiang, Lu. Magvit: masked generative video transformer. 2023. URL: https://arxiv.org/abs/2212.05199, arXiv:2212.05199. 1
- Yu, Lijun, Lezama, José, Gundavarapu, Nitesh B., Versari, Luca, Sohn, Kihyuk, Minnen, David, Cheng, Yong, Birodkar, Vighnesh, Gupta, Agrim, Gu, Xiuye, Hauptmann, Alexander G., Gong, Boqing, Yang, Ming-Hsuan, Essa, Irfan, Ross, David A., and Jiang, Lu. Language model beats diffusion – tokenizer is key to visual generation. 2024. URL: https://arxiv.org/abs/2310.05737, arXiv:2310.05737. 1
- Zeghidour, Neil, Luebs, Alejandro, Omran, Ahmed, Skoglund, Jan, and Tagliasacchi, Marco. Soundstream: an end-to-end neural audio codec. 2021. URL: https://arxiv.org/abs/2107.03312, arXiv:2107.03312. 1
- Peebles, William and Xie, Saining. Scalable diffusion models with transformers. 2023. URL: https://arxiv.org/abs/2212.09748, arXiv:2212.09748. 1
- Gupta, Agrim, Yu, Lijun, Sohn, Kihyuk, Gu, Xiuye, Hahn, Meera, Fei-Fei, Li, Essa, Irfan, Jiang, Lu, and Lezama, José. Photorealistic video generation with diffusion models. 2023. URL: https://arxiv.org/abs/2312.06662, arXiv:2312.06662. 1
- Razavi, Ali, van den Oord, Aaron, and Vinyals, Oriol. Generating diverse high-fidelity images with vq-vae-2. 2019. arXiv:1906.00446. 1
- Esser, Patrick, Rombach, Robin, and Ommer, Björn. Taming transformers for high-resolution image synthesis. 2021. URL: https://arxiv.org/abs/2012.09841, arXiv:2012.09841. 1
- Ho, Jonathan, Jain, Ajay, and Abbeel, Pieter. Denoising diffusion probabilistic models. 2020. arXiv:2006.11239. 1
- Rombach, Robin, Blattmann, Andreas, Lorenz, Dominik, Esser, Patrick, and Ommer, Björn. High-resolution image synthesis with latent diffusion models. 2022. URL: https://arxiv.org/abs/2112.10752, arXiv:2112.10752. 1
- Song, Yang, Sohl-Dickstein, Jascha, Kingma, Diederik P., Kumar, Abhishek, Ermon, Stefano, and Poole, Ben. Score-based generative modeling through stochastic differential equations. 2021. URL: https://arxiv.org/abs/2011.13456, arXiv:2011.13456. 1 2
- Bengio, Yoshua, Yao, Li, Alain, Guillaume, and Vincent, Pascal. Generalized denoising auto-encoders as generative models. 2013. URL: https://arxiv.org/abs/1305.6663, arXiv:1305.6663. 1
- Goodfellow, Ian J., Pouget-Abadie, Jean, Mirza, Mehdi, Xu, Bing, Warde-Farley, David, Ozair, Sherjil, Courville, Aaron, and Bengio, Yoshua. Generative adversarial networks. 2014. URL: https://arxiv.org/abs/1406.2661, arXiv:1406.2661. 1