One of the most underrated changes that the recent AI models made possible is data transformation for unstructured data. For the purpose of our discussion, we loosely say that structured data is tabular data, and unstructured data is binary blobs. For example, free form texts, images, and audios are unstructured. Before the recent transformer base LLMs and vision-language models, extracting useful information from unstructured data requires purposely engineered pipelines. With the power of the latest model, many data points could be extracted by selecting a model and setting a prompt. For example, say we want to get the key financial metrics (e.g. profit margin, revenue growth, and debt ratio) from annual reports. In the past, this is a full pipeline that is custom built and validated. It is not something that could be done in a few hours.It is now conceivable that this is just a SQL query that only requires a few minutes to write.
Let do a short short review of analytics databases. I had an old post on this topic that discussed the realtime and batch mode divide, and at the time, I implicitly ignored unstructured data because established analytics solution do not handle binary blobs. In this note, we focus on structured vs. unstructured data. To simplify discussion, I also ignore analytics solutions tailored to transactions, caching, and streaming processing, e.g. mysql, redis, kafka. For structured data, the most popular options are Hive, Iceberg, Delta Lake, Snowflake. For unstructured data, they are almost always stored in object store as S3, Google Cloud Storage, or Azure Object Store. Analytics databases are designed to store and process large amount of structured data. Data is a table where each column has a defined type such as text, number, or boolean. Each table scales to trillions of rows or beyond. A single table could have petabytes or data1. The query pattern is something logically equivalent to SQL statements. Query execution is equivalent to batch processing. The most popular query engines are MapReduce, Tez, SparkSQL, Presto, Flink, and Ray. Most databases support a variety of these engines. For example, Hive, Iceberg, and Delta Lake all support Presto, Flink, and Spark. In many ways, these solutions are similar2.
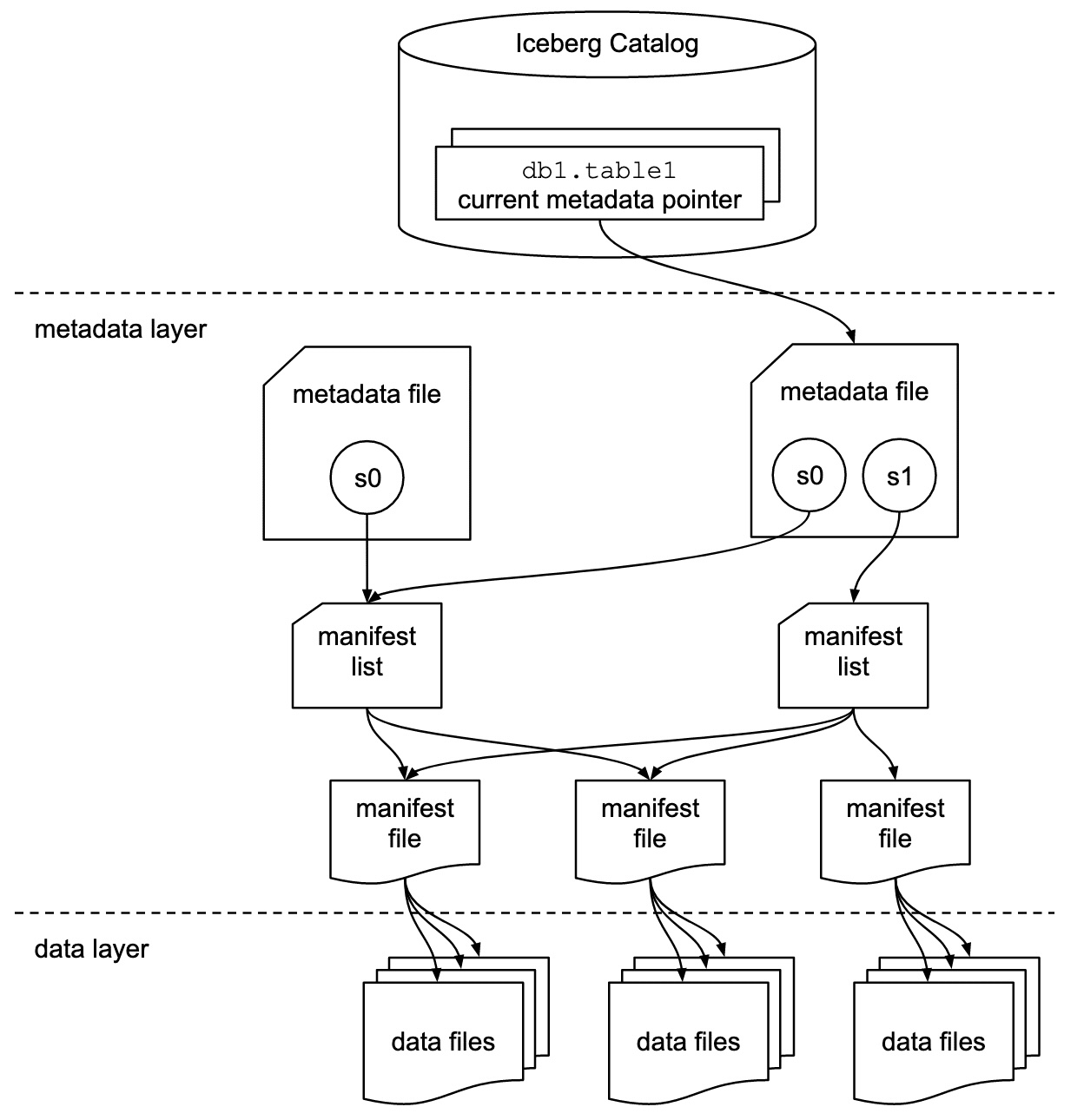
I will use Iceberg as an example to illustrate the key components a data analytics solution. A workin Iceberg deployment has three components: data, metadata, and query engine. Data are stored as parquet files in an distributed file system or an object store. A table’s metadata layer is managed by metadata files, which manage manifest files, which manage manifest lists, which manage data files. All four of these file types (metadata files, manifest files, manifest list, and parquet files) contain some sort of hints, e.g. partitions, column information, value ranges or bloom filters, that are use for skipping data3. Query execution first filters data and then apply some compute actions. They are translated to a distributed compute engine such Spark and Presto.
Object stores do not offer analytics capabilities. Object stores could be viewed as key-value store or a distributed file system. When it is viewed as a key-value store, we should not be confused it as a low latency distributed key-value store in the vein of dynamodb, aerospike, or distributed Redis. Object store is not meant to be used for read/write 10 bytes object millions of times per second. Another way to look at an object store is that it is a horizontally scaled out file system. In fact, most of the previously mentioned analytics database use a object store to as the storage backend for data files. Object store is extremely simple yet powerful. It is a foundational component of almost all modern data platforms. However, in order to get useful information out of billion or trillion of binary blobs stored in object store, we usually have to build custom data pipelines to extract information.
In the past, we only bother to run queries on structured metadata because it is expensive to extract useful information from unstructured data. It requires a lot of validation to get each extraction to be sufficiently high fidelity. With VLM and LLM, each new question is literally just another question written in plain English. Working with unstructured data is no longer restricted to teams with expensive engineering talents. Anyone should be empowered to ask meaningful questions and be given the ability to execute those queries. Anyone who is willing to execute SQL had been able to get meaning out of structured data. The data transformation from unstructured from structured should be just as easy 4.
The most common solution to get analytics from unstructured data is to write one-off custom batch jobs. The batch jobs are written as distributed data processing programs, sometimes run directly on VMs, on top of kubernetes, or integrated with distribute compute frame work like Spark or Ray. The job create new structured data, which could combined with existing tables to generate reports or new datasets to be used for training or other data science needs. For example, a team has a trillion of binary objects, e.g. texts or images. The team continually adds new data points because the team has new documents. The team continually extracts information, e.g. new questions are asked about the text documents or the images. The newly extracted metadata is combined with existing metadata, all expressed in SQL, to generate new reports or training datasets. A reasonable solution is to use Iceberg to store metadata and S3 to store binary blobs. When new data comes in, they go through a data processing pipeline, which is its own independent system. The processing pipelines generate metadata and ingest into Iceberg. To ask new questions about the documents, we create new processing pipelines to generate additional metadata to be merged or append to IceBerg. We run SQL queries in Iceberg to generate reports or training datasets5. This kind of system is functional but not ideal. The processing pipeline needs be built, maintained, and execute. It would require dedicated engineering know-how. It also slows down iteration. Multiple components have to be executed and monitored separately. Data users such as business analysts, data scientists, AI researchers who are not also pipeline builders could learn to use the system by ways of better documentations or trainings. But in practice, it invariably requires cycles by someone with deep knowledge of the engineering pipelines.
Snowflake is the one of the few solutions that attempts to give out-of-the-box analytics capability to unstructured data. It allows users to write User Defined Functions to process binary objects. However, it still feels that its unstructured data processing capability is an independent feature from its core SQL analytics. It does not integrate key-value object references directly with its tabular table. UDF is defined in Java. It is hard to translate AI models into SQL functions.
I would want to see an analytics solution that integrates tabular metadata with arbitrary binary blobs. The user experience goes something like the following. Data storage is table that supports both structured data and binary blobs. For example, we have a table of text documents and images. We have 10 columns of metadata for each object. There is a column that references its binary data as a S3 key. Users want to create a new datasets that has 3 columns from the table and two additional columns extracted from the binary blobs. They could write a statement similar to
CREATE FUNCTION are_people_surfing(file BINARY)
RETURNS BOOLEAN
...
CREATE FUNCTION is_there_kid_in_the_image(file BINARY)
RETURNS BOOLEAN
...
SELECT col1, col2, col3, are_people_surfing(img_col), is_there_kid_in_the_image(img_col) FROM table
It might looks like it is only an incremental change from existing analytics solutions such as Snowflake and Iceberg. The key components are: an unified view for both structured and unstructured, enabling analytics of binary blobs at query time, and integrating LLM and VLM models in SQL queries. An out-of-the-box data analytics solution with these features would reduce the engineering overhead for many data engineering teams6. Furthermore, it will empower many data users to directly work with data by asking plain English questions. I have personally seen many different teams have this need and devoted sizable engineering resources to fulfill that need. These teams have a lot of unstructured data would are cumbersome to use with existing out-of-the-box solutions.
Footnotes¶
- In theory, it could go up to exabyte, but I have not personally use these solutions at that scale. ↩
- I don’t really buy the marketing hype of lakehouse. Hive was the standard open source data warehouse solution for many years. Marketing folks coined the term lakehouse to differentiate the new comers (e.g. Iceberg, Delta Lake, and Hudi) from existing data analytics solution, which used to be called data warehouse. To me, Iceberg is a straight-forward next iteration of Hive, and it is solving mostly the same set of problems with additional optimizations. It is silly to create a new category because the problem statements have not changed. ↩
- A query is able to first take advantage of the various metadata available to filter out unnecessary data files to use. Finding files is just working through the metadata files, it is done locally and does not involve a distributed compute engine; this is known as scan planning. For example, manifest list contains value ranges, manifest files has column level stats, and parquet file has row groups, each row group has column level stats. ↩
- Furthermore, it is becoming more and more robust that we could create SQL queries just by prompting. The next iteration is clearly that using plain English, we could create datasets or reports by just using English for both structured and unstructured data. ↩
- The most popular framework to build these processing pipeline is Ray, especially if GPU-heavy models are used frequently. It could be done with Spark. It is also not uncommon to write distributed jobs from scratch combining with simple job queues backed by Redis or MySQL. ↩
- Let us sketch out how to build this solution with popular open source components as of the writing of this note. We pick S3, IceBerg, and Ray to be the backbones. Iceberg is the metadata store. S3 could be viewed as an internal component of Iceberg. Ray is the compute engine. The main reason to choose Ray here is that we want to be able to integrate AI models and SQL executions. As of the writing of this blog, Ray dataset does not provide a SQL API for writing data transformations. We need to build three major components to get to a working version: translating SQL statements into Ray Dataset execution and connecting models to user defined SQL functions. ↩