ChatGPT has become one of the most popular AI assistants. It is a fixed, general purpose model. That is by design because it learns from mostly texts in the public domain. This applies to open source LLMs as well, e.g. T5, LLaMA, and falcon. However, there are many reasons to build AI assistants that specialize in limited knowledge domains. For example, I might want to talk an AI assistant specific to home purchasing, an assistant is limited by a company’s private corpus of documents, or a personal assistant that has access to my private emails, texts, and calendar. In this post, I will discuss the techniques relevant to building a domain-specific AI assistant.
An LLM accesses private information in one of two ways. The information could be baked into model parameters, and then the chatbot retrieves relevant information through prompting. This requires the LLM to be trained on private data after it acquires its general comprehension capabilities. The other way is to provide the domain specific knowledge as input context. The information retrieval step is performed outside of the language model. It could be calls to external APIs or searches of a document store.
Knowledge Infusion Through Model Training¶
LLMs could answer a wide range of common questions directly. Their breadth of knowledge could be comparable to a search engine. LLMs memorize information by applying some pretraining objectives to a large corpus of data. The data sources are usually a mixture of internet text, books, and other various public text corpus.
It is important to note that an LLM only loosely absorbs information from the training corpus. There is no guarantee that any one piece of data will be 100% burned into model parameters. Even the largest neural model is not likely to incorporate information in any predictable or uniform way. There are estimates about those information retention rates. For example,
CIJ+23
quantifies the some lower bound to be 1%. It is impossible to exactly quantify this retention rate. The memorization mechanism is hard to know for sure. We only know that a large neural model could learn from simple pretraining objectives.
PSC21
discusses the limit of knowledge acquisition through masked language pretraining objectives. We are still early in our understanding of how LLMs work and how to properly perform precise memory infusion, extraction, or modification.
There are many unsupervised training techniques to infuse knowledge and capabilities to LLMs. The most common is the various forms of masking spans. For example, next token prediction, next sentence, and random masked spans are the most popular and common pretraining objectives.

If the private domain contains structured knowledge, e.g. knowledge triplets, one could devise a masking strategy that focuses on key concepts and relationships (
SWF+21
and
MDAJ22
).

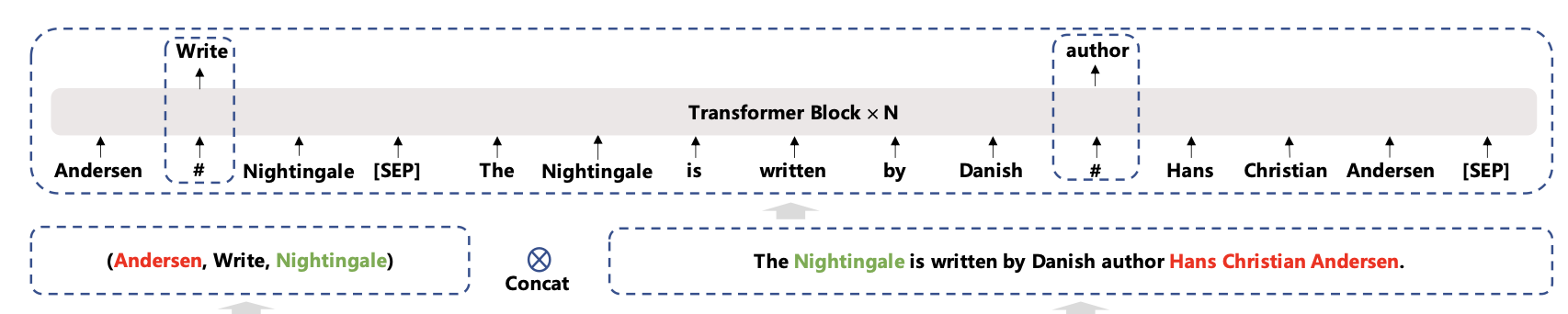
Other objectives could be predicting sentence ordering. The model is asked to recover the correct ordering from a randomly permuted sentence order. Another objective could be sentence distance. A model takes two sentences as input and predict the category in the set of adjacent, nonadjacent but same document, and not in the same document.
Other than using unsupervised training objectives, it is also possible to update the model parameters through the use of synthetic data with a task-specific fine-tuning objective. Some LLMs, either the one undertraining or an external LLM, could be used to generate input and target pairs from raw texts. The input and target pairs could be in the form of question and answers, question and supporting passages, queries and topic classifications, etc. The model is then trained on these labeled data.

LLM Information Extraction Techniques¶
There are different techniques to extract information from model parameters. The most obvious approach is through prompt engineering. The most well-known prompt techniques are few-shot learning and chain-of-throught prompting.

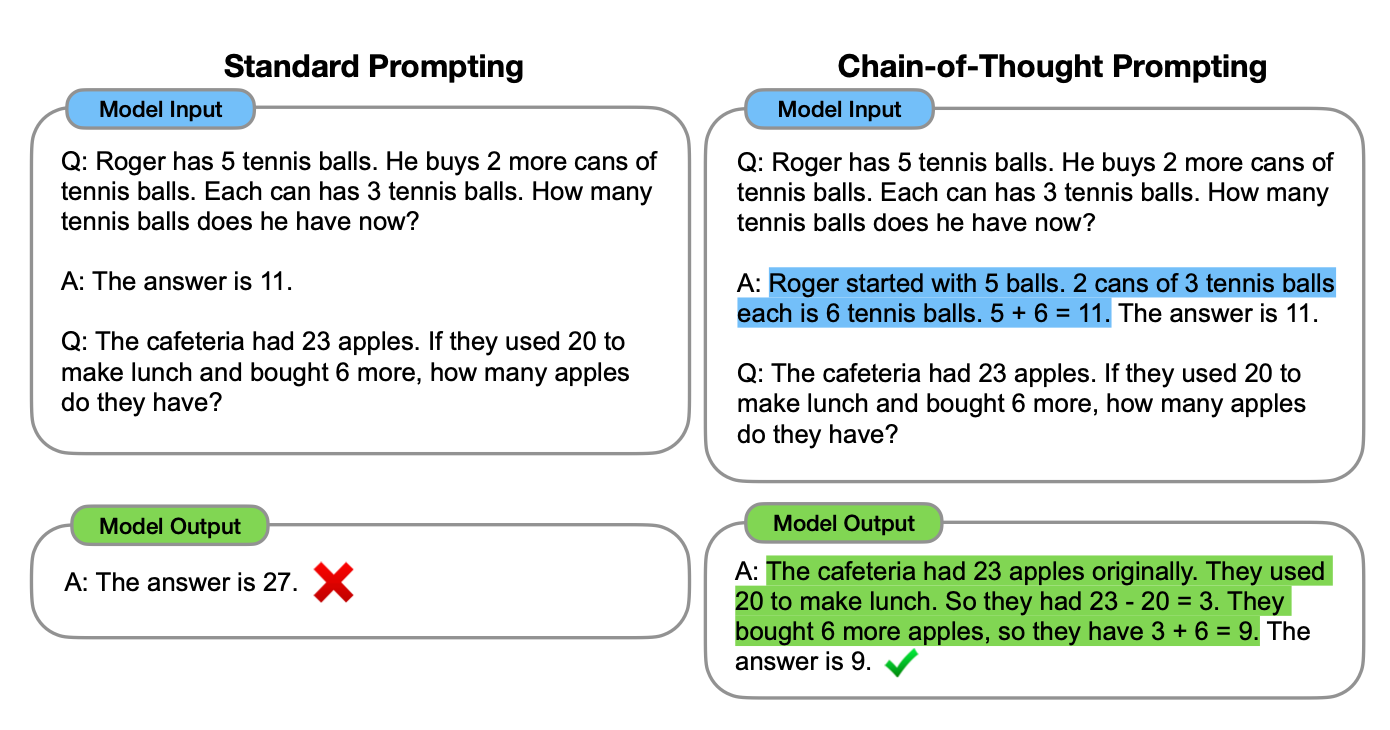
There are additional variations. For example, the few-shot could be combined with synthetic example generation. The few examples could be modified to be a recitation-augmented prompt, as proposed by
SWT+23
.

Other than better prompts, there are other ways to improve information extraction from model parameters.
WWS+23a
proposes sampling multiple outputs and choosing the most consistent answer from the set. One could also ask the LLM to produce multiple relevant recitations about the queries and use those recitations as context for the LLM to make a final output.
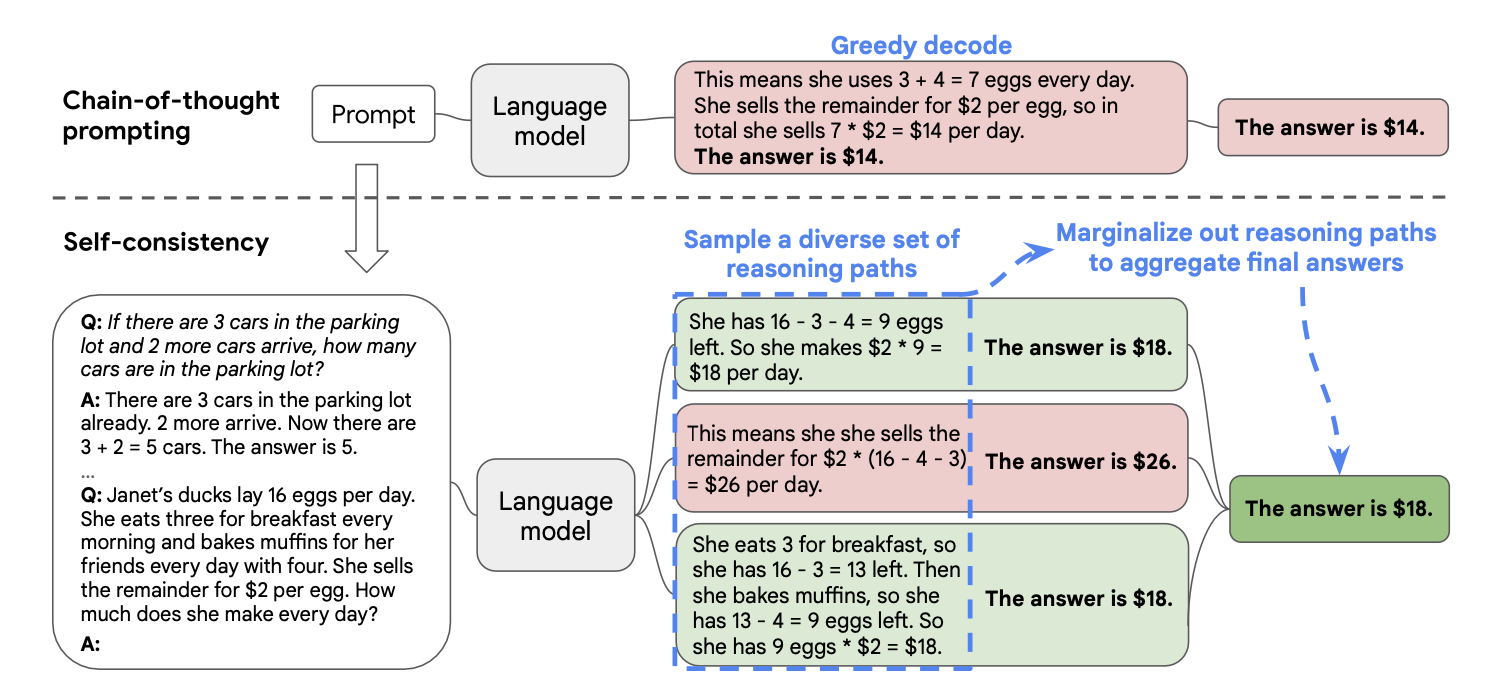
The sampling and prompting techniques could be combined in any permuted order. For example, one could prompt the LLM to sample multiple recitations and keywords that describe the input query. The recitation passages could be deduplicated by or combined keywords before being used as examples in the final prompt fed to the LLM. In many ways, once an LLM completes learning what it could through its training stages. We can use prompt engineering techniques or modify the last layers to direct the LLM to squeeze information from its parameters and explore different outputs.
Retrieval-Augmentation¶
The easiest way to create a domain specific AI assistant is using a retrieval step to add a context to the prompt. This approach is commonly described as retriever-reader in the open book question-answering literature. This framework works well for AI assistants as well. The foundational model provides general reasoning and comprehension capabilities, and the information required to answer user queries is provided in the context. The key advantage of this approach is the retrieval step is very predictable and explicit. It is a much more efficient and reliable information retrieval procedure than prompting an LLM to find information stored in its parameters. However, the context window could become a limiting factor. The responses is likely to be superficial and read like a summary of the provided context. The LLM could not draw patterns, nor could it synthesize data from the entire corpus relevant to the query. The enterprise knowledge chatbot created by Glean follows this pattern.
The retrieval step is text search, which could use semantic embeddings powered by LLMs or vanilla lexical search. See my previous post on document search. There are additional ways to modify this setup. For example, ZYD+22 proposes appending synthetic data to be indexed with the raw document to improve retrieval effectiveness.
External Tools¶
The retrieval step is an example of using external tools to complement the knowledge implicitly stored by the LLM. OpenAI’s plugin and function calling API is another example of piecing together external tools to be part of an AI assistant. The basic framework is simple. Before the LLM produces the response, it determines whether it should perform external API queries. The set of available APIs could vary from application to application. The LLM can turn the original query into inputs to external APIs, and the API’s responses are converted into context as part of the final prompt. SDYD+23 and PGH+23 test similar schemes to validate zero-shot performance across a variety of NLP tasks.
Such a component could be built and patched to any open-source LLMs. There are two key NLP tasks that this component requires. One is a classification task on whether the LLM needs to use the external API given a query. The other task is transforming the query into compatible API inputs. This framework extends the AI assistant’s ability to both retrieve relevant data and perform actions on behalf of the AI user.
Final Thoughts¶
AI assistants had not been very useful until the recent progress in LLMs. However, ChatGPT is just the beginning. I expect that more and more applications will enable meaningful and easy-to-use assistant user interface. These assistants won’t be general-purpose the same way that web search or ChatGPT are. These assistants will be limited in scope and domain-specific to the application. Chatbot style interaction is a natural extension to an search box, which has been a standard feature for the past decade. The next generation of applications will use chatbot as the interface for both information retrieval as well as performing actions.
Footnotes¶
Citations
- Carlini, Nicholas, Ippolito, Daphne, Jagielski, Matthew, Lee, Katherine, Tramer, Florian, and Zhang, Chiyuan. Quantifying memorization across neural language models. 2023. arXiv:2202.07646. 1
- Porada, Ian, Sordoni, Alessandro, and Cheung, Jackie Chi Kit. Does pre-training induce systematic inference? how masked language models acquire commonsense knowledge. 2021. arXiv:2112.08583. 1
- Tay, Yi, Dehghani, Mostafa, Tran, Vinh Q., Garcia, Xavier, Wei, Jason, Wang, Xuezhi, Chung, Hyung Won, Shakeri, Siamak, Bahri, Dara, Schuster, Tal, Zheng, Huaixiu Steven, Zhou, Denny, Houlsby, Neil, and Metzler, Donald. Ul2: unifying language learning paradigms. 2023. arXiv:2205.05131. 1
- Sun, Yu, Wang, Shuohuan, Feng, Shikun, Ding, Siyu, Pang, Chao, Shang, Junyuan, Liu, Jiaxiang, Chen, Xuyi, Zhao, Yanbin, Lu, Yuxiang, Liu, Weixin, Wu, Zhihua, Gong, Weibao, Liang, Jianzhong, Shang, Zhizhou, Sun, Peng, Liu, Wei, Ouyang, Xuan, Yu, Dianhai, Tian, Hao, Wu, Hua, and Wang, Haifeng. Ernie 3.0: large-scale knowledge enhanced pre-training for language understanding and generation. 2021. arXiv:2107.02137. 1
- Moiseev, Fedor, Dong, Zhe, Alfonseca, Enrique, and Jaggi, Martin. Skill: structured knowledge infusion for large language models. 2022. arXiv:2205.08184. 1
- Saad-Falcon, Jon, Khattab, Omar, Santhanam, Keshav, Florian, Radu, Franz, Martin, Roukos, Salim, Sil, Avirup, Sultan, Md Arafat, and Potts, Christopher. Udapdr: unsupervised domain adaptation via llm prompting and distillation of rerankers. 2023. arXiv:2303.00807. 1
- Brown, Tom B., Mann, Benjamin, Ryder, Nick, Subbiah, Melanie, Kaplan, Jared, Dhariwal, Prafulla, Neelakantan, Arvind, Shyam, Pranav, Sastry, Girish, Askell, Amanda, Agarwal, Sandhini, Herbert-Voss, Ariel, Krueger, Gretchen, Henighan, Tom, Child, Rewon, Ramesh, Aditya, Ziegler, Daniel M., Wu, Jeffrey, Winter, Clemens, Hesse, Christopher, Chen, Mark, Sigler, Eric, Litwin, Mateusz, Gray, Scott, Chess, Benjamin, Clark, Jack, Berner, Christopher, McCandlish, Sam, Radford, Alec, Sutskever, Ilya, and Amodei, Dario. Language models are few-shot learners. 2020. arXiv:2005.14165. 1
- Wei, Jason, Wang, Xuezhi, Schuurmans, Dale, Bosma, Maarten, Ichter, Brian, Xia, Fei, Chi, Ed, Le, Quoc, and Zhou, Denny. Chain-of-thought prompting elicits reasoning in large language models. 2023. arXiv:2201.11903. 1
- Sun, Zhiqing, Wang, Xuezhi, Tay, Yi, Yang, Yiming, and Zhou, Denny. Recitation-augmented language models. 2023. arXiv:2210.01296. 1
- Wang, Xuezhi, Wei, Jason, Schuurmans, Dale, Le, Quoc, Chi, Ed, Narang, Sharan, Chowdhery, Aakanksha, and Zhou, Denny. Self-consistency improves chain of thought reasoning in language models. 2023. arXiv:2203.11171. 1 2
- Zhou, Yujia, Yao, Jing, Dou, Zhicheng, Wu, Ledell, Zhang, Peitian, and Wen, Ji-Rong. Ultron: an ultimate retriever on corpus with a model-based indexer. 2022. arXiv:2208.09257. 1
- Schick, Timo, Dwivedi-Yu, Jane, Dessì, Roberto, Raileanu, Roberta, Lomeli, Maria, Zettlemoyer, Luke, Cancedda, Nicola, and Scialom, Thomas. Toolformer: language models can teach themselves to use tools. 2023. arXiv:2302.04761. 1
- Peng, Baolin, Galley, Michel, He, Pengcheng, Cheng, Hao, Xie, Yujia, Hu, Yu, Huang, Qiuyuan, Liden, Lars, Yu, Zhou, Chen, Weizhu, and Gao, Jianfeng. Check your facts and try again: improving large language models with external knowledge and automated feedback. 2023. arXiv:2302.12813. 1