This short post is about how to train deep neural models that do not fit into a single GPU.
Each GPU has limited memory. While it is possible to offload the model to CPU’s main memory or even disk, it slows down the training and has limited scalability. The next obvious solution is to use multiple GPUs. That is limited to at most 1 order of magnitude scaling. The only viable solution is partitioning a model to a cluster of GPU machines, where data and model update communications go through the network.
Note that distributed data parallelism only speeds up training. It splits up each batch into different batches. Batches are processed by different GPUs concurrently. An all-reduce operation of the scattered optimizer states allowes each GPU device to calculate one round of parameter update as if each GPU has processed all the data. This approach speeds up training, but it does not allow the model to scale beyond a single GPU.
As model size grows, the only solution is to split up the model. The model includes model parameters, gradients, gradient variances, momentums, activations, and other residual memory requirements. The simplest solution is to naively partition the model layer by layer. The model is expressed as a sequence of layers, where layers could be distributed to GPUs. The model is computed layer by layer sequentially. It is not hard to see that GPUs idling is a critical efficiency issue.
Pipelining aims to mitigate the GPU idling problem. The strategy is to concurrently process multiple smaller batches to enable all GPUs to have some work to do. It does not fully optimize GPU utilization.

The partitioning could be more fine-grained. The tensor computation could be split into GPUs. See 3 for a technical description. Pytorch supports tensor computation across GPUs through its RPC and distributed tensor framework. This strategy is hard to adapt because it does not generalize well to models written with a high level API. Each model has to be explicitly configured to split up small computation unit. It also does not describe how the computation should be pipelined and ordered, likely leading to efficiency issue.
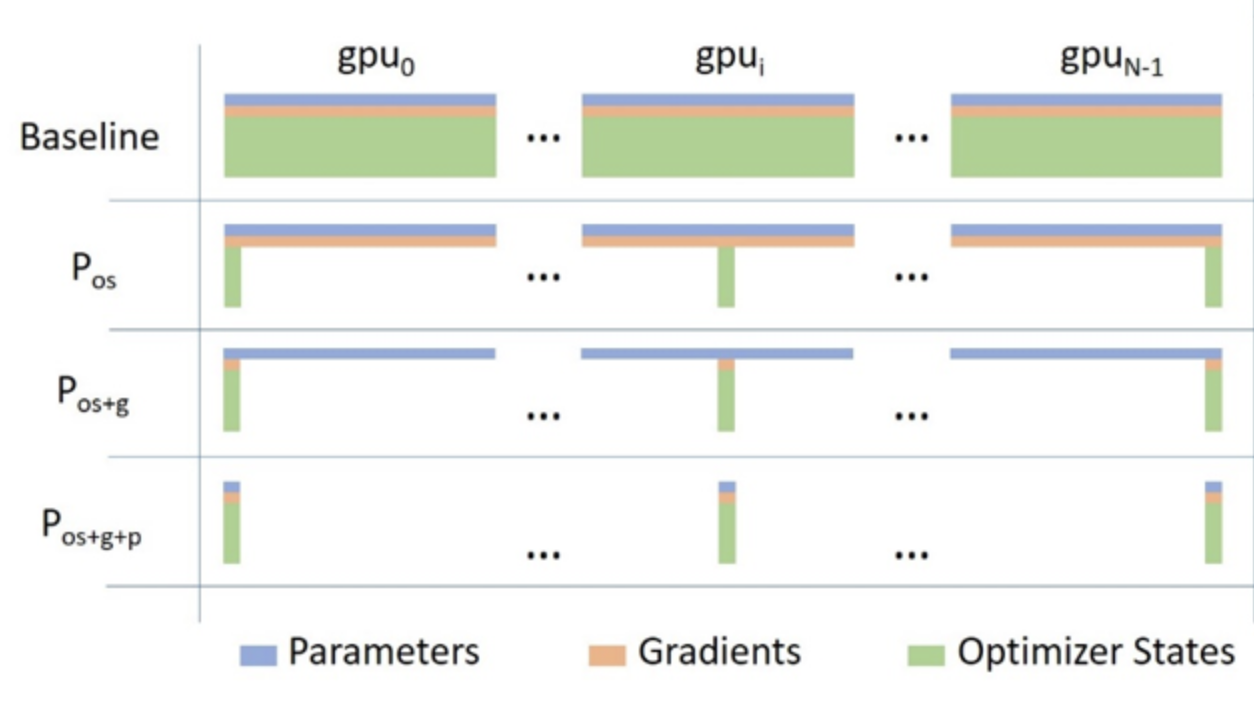
Deepspeed pioneered the ZeRO (Zero Redudancy Optimizer) distributed training paradigm that combines data and model parallelism. The model is sharded and distributed to GPUs. Each GPU device processes a different data batch. Each device acquires a model shard as necessary to perform a forward and backward pass. The updates are broadcast to the appropriate shard owners once the update computations are completed. Each device only retains its own shard after an update. Deepspeed releases this optimization library. Pytorch’s FSDP is another framework that follows this optimization strategy. See 4 for more detail. This paradigm is the most promising if one has to perform domain adaption with large private text corpus on the latest state-of-art large models (e.g. falcon, LLaMA, and PaLM).
References
-
OpenAI’s blog post on training large neural networks
-
The “Switch Transformers” paper discusses data, model, and expert parallelism extensively ( 1 ).
Citations
- Huang, Yanping, Cheng, Youlong, Bapna, Ankur, Firat, Orhan, Chen, Mia Xu, Chen, Dehao, Lee, HyoukJoong, Ngiam, Jiquan, Le, Quoc V., Wu, Yonghui, and Chen, Zhifeng. Gpipe: efficient training of giant neural networks using pipeline parallelism. 2019. arXiv:1811.06965. 1
- Narayanan, Deepak, Shoeybi, Mohammad, Casper, Jared, LeGresley, Patrick, Patwary, Mostofa, Korthikanti, Vijay Anand, Vainbrand, Dmitri, Kashinkunti, Prethvi, Bernauer, Julie, Catanzaro, Bryan, Phanishayee, Amar, and Zaharia, Matei. Efficient large-scale language model training on gpu clusters using megatron-lm. 2021. arXiv:2104.04473. 1
- Zhao, Yanli, Gu, Andrew, Varma, Rohan, Luo, Liang, Huang, Chien-Chin, Xu, Min, Wright, Less, Shojanazeri, Hamid, Ott, Myle, Shleifer, Sam, Desmaison, Alban, Balioglu, Can, Nguyen, Bernard, Chauhan, Geeta, Hao, Yuchen, and Li, Shen. Pytorch fsdp: experiences on scaling fully sharded data parallel. 2023. arXiv:2304.11277. 1
- Fedus, William, Zoph, Barret, and Shazeer, Noam. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity. 2022. arXiv:2101.03961. 1